ChatGPT
Mind blown. When it comes to anything regarding IT, I consider myself a seasoned veteran and there aren't many things that astound me. I went from “I don't know what all that fuss is about” to “I can't live without it” in about two hours. It's like Google, but instead of personalised ads you get personalised responses. For me it might be the biggest jump since the internet itself.
I love I can be super lazy in writing prompts, it doesn't care about typos or abbreviations and is very context aware, so I don't have to write extra words. It will grasp terminology, acronyms, newspeak, slang or even mixed languages! It can translate no problem and its sentence elaboration helps my learning Japanese immensely.
ChatGPT Logo
Asked for source, it gave me the source. I asked for links, gave me the links. Many of which were 404 and I thought they simply changed since the learning cutoff, but after a while I started to suspect those links were actually hallucinated by the language model.
Quantum computing explained, simple WebGL 3d engine or basic isometric engine created. There are devs with mobile apps accepted to the stores with zero lines of code written by themselves. It's endlessly helpful with regular expressions, I just describe what I need and the model is often correct on it's first try.

Neural network schema
Although I sometimes struggle, it's still VERY helpful. It's much quicker to simply ask ChatGPT, which will usually respond on topic and distills the info into four paragraphs. I don't have to click on dozens links, half of which doesn't even contain the keywords for some reason.
I kinda like bouncing off ideas or asking GPT to provide lists of things, like when I was looking for inspiration for Qard, I asked: "how they do it in all major game engines?".
It really excels for "easy" programming tasks in languages I'm not that familiar with (like code to download and unzip file), or to translate code from one language to another. But it could be frustrating to have a specific code in mind and force GPT to comply. In a few instanced it started to loop around, disregarding any further prompts.
It's kinda strange, but while many others complain it plagiarizes a work of thousands, I'm so mesmerized by the language model's capabilities I've started to think how to give it even more sources. Maybe QB data will come in handy for a plugin?
Despite all it's flaws, like hallucinations, it's very handy sidekick. I even tried to task it with a few topics for this blog :-)
QB in JSONs
I finally created a basic backend for converting original QB data in Data Particle structure to the Qedy-style JSON structure. It will take some time to convert those millions of rows, but I'm in no rush.
QB to elems
Even I still adore Data Particles I “invented” almost 10 years ago, without proper tools (I struggle to create) it's quite hard to manage the data. I encounter it from time to time when I need to fix some order in our intranet app.
So for QB I decided to move from Data Particles to JSON structure I created for Qedy. It suits the purpose rather well and I can improve it to be mutually beneficial.
I created a simple parser, that runs for every ID, which is time consuming, but there's no rush. Data Particles will remain in use for caching and in the regular model they will perfectly fit as attributes.
This way all the hardships disappear, because it won't be primary data. When an error occurs, it would be possible to simply delete all the invalid data and create it from the JSONs.
Indefinite date
string instead of date type (YYYYMMDD, 2017000 = in year 2017, 20171100 = in Nov 2017
advantage of date type is size, a DATETIME value uses 5 bytes for storage, TIMESTAMP requires 4 bytes, DATE just 3 bytes.
Least amount of space: in one column DATE, in another column have TINYINT precision for that date. It could either indicate what part of it is not precise (like unknown day, unknown day and month, in that decade, in that century) or have a spread.
GeoQetriX DDD
I already wrote about GeoQetriX, but what’s with the three D-s? Well, 3D sounds quite familiar, doesn’t it? :-) When I started to fool around with Microsoft XNA’s successor, MonoGame, I obviously dipped into 3D graphics as well. Great source of knowledge are Remer’s XNA Tutorials.
I’m still quite new to 2D, so a lot about 3D is total gibberish to me so far, but a lot of things already rings a bell – like the only available shape is a rectangle or terrain is created by a mesh (of rectangles). I know what a vector is, so to get the idea of vertices was no big deal.
But the amount of code, required for the simplest tasks to draw, are somehow incomprehensible to me. In 3D there’s a lot of information required, that’s no brainer, but until this I’ve been always able to shorten the code to just a few lines.
Another option would be to use WebGL, instead of XNA. All the major browsers are already supporting it and there are some great frameworks to help with the complexity of 3D.
GeoQetriX Map Roadmap
Of course I know it will never come even close to Google Maps or OpenStreetMap and I don’t even want to. My personal motivation is to be able to use my own maps for general purposes, like place locators.
So, I’m going to include administrative divisions, preferably up to city boroughs. Plus major roads, major railroads, major rivers and major streets. I have to come up with some compression, I’d like to be able to define, how detailed the export (SVG, PNG) should be. So far I can do it with all lines loaded, which is quite resource inefficient.
Qarate
I like watching TV series, my list of favorites is quite long. I also like to re-watch them, from time to time, but sometimes only the good episodes. I had a list of good ones on my personal wiki, but it was boring to note them every time (and when I watch multiple episodes in a row, I simply forget to note it and then I forget which one was the good one).
I did some research and found Trakt and became a happy user, because rating was quick and easy enough for me to actually do it.

Trakt logo
One day Trakt creators upgraded the website and rating system was still in “to-do”, so now I had nowhere to rate. I tried to find any suitable replacement, but without any success. I also use EpisodeCalendar, which only tracks watched episodes – without rating.
So, out of frustration, I added a new table “rating” to my personal wiki. It allowed me to rate not only episodes, but anything else – movies, songs, cars, vacations, etc. I was so pleased I thought this might be a nice service for others to use as well.
The biggest drawback was, that I had to enter the thing I was rating, mostly episode identification. I don’t want my users to add anything. First of all, it’s not quick and easy. Second of all, it will get wrong and duplicate (sorry, users...). It would require something, where all such data already is. Oh, wait!
I’m building qb for several years now and it will be the perfect marriage: a big database with “everything”, plus a website, that allows you to rate anything. Sounds great.
I looked for a fitting name, which starts with “Q” and contains “rate” and in the shower (which is a common place for ideas for many people, according to one article I read) I thought of “Qarate”.
You can pronounce it as “Karate” (martial art) or “Carat” (unit of mass for gems and pearls) or “Karat” (fineness of gold). Therefore users may form dojos and level as gem rarity and belt colors (like blue diamond is more, than black sapphire).

Rating system will consist of 5 grades with matching score for that entity: +2 (excellent), +1 (good), 0 (meh), -1 (bad) and -2 (terrible). User may have limited +3 grades (the best), which can be used to mark a notable thing of it’s kind, like one episode in a TV series season.
And it will have positive effect on qb as well, because in the original release I included user generated content into the database, like comments or ratings, which I didn't like. Now I can separate data from user contaent into two different products.
GeoQetriX Map
I presented the idea of GeoQetriX [2013/05#geoqetrix more than a year ago], but finally I got the urge to make it done. I’m gonna to redo my website about “USA thru Czech Eyes”, so I wanted interactive maps. I found some JavaScript libraries, based on Raphaël, and using SVG paths for countries.
So I downloaded some countries. And some more countries. And this country, this one, and... but at least one of them was missing. So, as one might expect, it brought me to an idea to do it on my own (to have them all). I’m gonna to need them anyway at some point, so why not now?
Because Google Maps JavaScript API is truly extraordinary, I didn’t think twice how I’m going to do the editor.
So. I put some geographical points (using markers) on the map and stored them in the database. They were basically major country border joints and major shore features. In the very first version, the editor generated SQL INSERT commands, which I executed manually in HeidiSQL.
Then, of course, I had to stop being lazy about DB support and created a script to generate JSON for markers on the map, later for lines as well. Markers and lines both have a type, with semantic meaning (shore border, inland border, division border...).
Except for the Google Maps I created a secondary output, into generated PNG. For debug purposes I assigned different colors to each type (blue for shore, red for inland, green for divisions, gray for subdivisions). And started clicking. And clicking... But after a while I was quite excited about the (still work-in-progress) result:
Along the way, I adjusted something here and there. The editor has to be very easy to use, because I guess I’m gonna spend quite a time in it. I want to have major roads and railroads, along with water.
I also had to use a projection for the map output. I chose Miller (EPSG:54003 – World Miller Cylindrical), because personally I like it the most; for me it’s the “classic” view.
Before the final alpha-stage map I did everything I planned to. Like placemark settings with a list of attached lines, with possibility to change type of the line, delete selected line or add a midpoint to a line.
The last thing is to define, what’s on each side of a line. At first I thought it will be the smallest unit possible (like a county, neighborhood or even a plot), but I kept thinking that querying the whole country may consist of thousands of geo-units.
After a while I realized that the other way around it would be much better, without losing much fidelity. So at this point I’ll define a country (or sea/ocean) for each line, if it’s a country border. Then state borders, county borders and so on. If I would like to draw a country, I simply ask for all lines with it’s ID.
Structured database of everything
In May 2011 I wrote publicly about QB for the first time, into a forum of Czech on-line magazine Lupa.cz, which focuses to internet. I wrote the post in my native Czech, so here I translated it for you to ejnoy:
Hello,
I have designed a universal system for structured data management to fulfill my frequent need for quickly retrieving specific information on the go. Services like Wikipedia don't suit me due to their complex nature, lack of data availability for the Czech Republic, or reluctance to record "every little thing."
The basic implementation can be found at http://q.q3x.net/ and besides the data database, it includes a few useful tools (unit and currency converter, whois, distances, etc.) that are further utilized by the system itself. For example, the data is stored in standard units and converted according to the selected language (e.g., English uses dollars, miles, ounces, etc.) when displayed, and additional calculations are performed if needed (population density, for instance). Instead of a traditional API, data can be obtained by selecting a rendering module for a specific format (e.g., TSV).
Personally, I utilize information about aircraft based on their registration (typically age), information about people (typically age), and places (typically population count). The system can also record the content of a library or books read with ratings, the same for movies, TV series, or music. Products can be found using the EAN, and if data is available, it shows where the product is cheapest nearby, how far it is, and how quickly I need to go to catch the bus heading there. The system can even handle a complete CMDB (Configuration Management Database); that's why it was designed in a decentralized manner with the option for interconnection.
The ultimate goal is to synthesize Wikipedia, Freebase, Wikia, WolframAlpha, along with local databases and something extra. There is no underlying business plan; it's not meant to be a mean to get rich but primarily for entertainment, relaxation, and an opportunity to avoid stagnation. However, I don't want to be the only one benefiting from the system, so I welcome questions, opinions, advice, feedback, and criticism... Thank you.
I'm aware that data is the alpha and omega, and I gather it in every possible way. Ideally, crowdsourcing would be the solution, but without a "crowd," it functions poorly. So please take the data with a grain of salt. Essentially, they are mainly for testing purposes, to evaluate performance and gradually refine the concept. And finally, I apologize in advance for any parse errors; it's a work in progress.
> Quote: Petr Hejl 25th May 2011, 18:57:27
> The plan is quite ambitious. The problem will be with the data because each database or website has almost a different format. I don't want to discourage you, but WolframAlpha has tried this and failed miserably. Unless you invent a universal parser...
I don't assume I would crawl the web with a crawler and extract structured data. That never generates a reasonable level of data cleanliness. In the beginning, I tried to write a DOM parser for Wikipedia, and even on a single project, there are so many exceptions that I eventually gave up. So the assumption is that data is populated with pre-prepared batches (there are tons of them online, typically XLS or tables in PDF) or manually (using suitable tools, which is not such a hassle).
Honestly, this whole endeavor was initially provoked by disappointment with the level of data on the internet, aiming to create a purely data-oriented platform with solid boundaries. I built a fully customizable application on top of the data model, which formed the basis of this entire concept. So from the very beginning, I assume that the primary source of data will be a keyboard or defined formats (VCF, GPX, XML, XLS, etc.) for which I already have import algorithms.
> Quote: Ondra 25th May 2011, 20:18:37
> 1) Not everyone is a geek (Is it for "normal people"? ;-)
> 2) http://www.uoou.cz
No, it's not :) Currently, I'm working on adapting it for "normal people," but I'm already quite distorted...
How does it differ from similar systems? I have given a lot of thought to personal data, but the information I worked with regarding this topic didn't contradict the current content. If you have more specific information, I would appreciate it and take the necessary steps. Otherwise, the data comes from publicly available sources.
FindTheBest.com
Holy cow, how did it manage to hide from me the whole time? I don’t remember how I came across this website, but I have to admit, when I spent a few minutes clicking here and there on it, I was truly dumbfounded.
It isn’t really IT, but it is so damn close to what I’m working at. Sure, I knew there’s a huge competition since I started, but all those freebases and wolfram|alphas were either different, ugly or hard to use. This is none of them. The only good thing for me is that the main turf for the website are mostly the States and I’m aiming higher.
On the other hand, they have a huge amount of pictures, awesome graphs, nice filtering options with excellent results interpretation, overwhelming wizard-like “assist me” function and much, much more.
When I shook the surprise off, I started to pick features I like and think how to implement them into QetriX.
- Classifications should have default icon and picture.
- For attributes there should be an information about what value (lower/higher) is better. A weights for this would be nice too.
- User friendly filtering, using not just values and check boxes, but nice min-max sliders as well. Domains will be handy here.
- Entity should me even more specific, with charts and tables.
- Related entities are necessary.
- Besides the main entity it would be handy to attach small info-box for related entities too, such as manufacturer, superior area unit, homeland etc.
- User ratings and comments would be there again. Comments with rating also (up/down vote, likes...).
I assume it’s also written in PHP, since /index.php returns no 404. I was trying to find their data sources, but I found only a simple statement: “We obtain our information from three sources: Public databases, primary sources (manufacturer websites) and expert sources.“ Well, sincerely I didn’t expect much more, since data sources are the main business secrets here.
Creeper Crawler
As I wrote earlier, I was confident I can collect data for the Particle Database by myself, but shortly I realized it’s just too much. So after a struggle I decided to make a web crawler for harvesting semantic data.
The decision of target platform was quick – PHP is not suitable, so .NET. At first I tried to customize some of those existing open source crawlers, but it was a pain. So ultimately I wrote my own. I don’t need any GUI, so simple console app was suitable.
It downloads plain text data (e.g. HTML page), using HttpWebRequest class, and extracts all links to other pages. For every use I can define a set of boundaries, so links out of these boundaries are thrown away. The rest are put into queue. Robots.txt and meta tags are a part of those boundaries as well.
Then crawler prepares data for parsing – strips off all unimportant parts and replaces or deletes some parts (like whitespaces). Then it checks for presence of defined string, indicating there are some data to extract. And finally, using regular expressions, structured data are extracted and send to server-side for further processing.
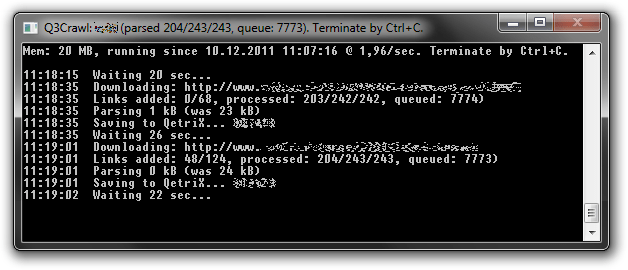
On server side is PHP script, which post-processes and saves data into database, finds relevant links to another entities and stores URL of data source to avoid duplicates.
Then crawler politely waits a while before loading next URL from queue, because I don’t want to overload these servers. And... that’s it! Simple, yet powerful.
Google Glass
People say that New York City you can either love or hate, noting in between. From buzzing around Google Glass I can say the same about this gadget. Even though I find myself on the side of “hate”, as I see it as a major breakthrough of my privacy, from QetriX’s point of view it’s a major opportunity. It’s exactly what I’m focusing on for QB – tiny pieces of important/interesting information on the go.
I can tell apart those opposing feelings easily, because my personal concern is about the built-in camera, whereas the opportunity is spurting from the head-mounted (or “heads up”) display.

Google Glass Explorer Edition
The true resolution of the display remains unknown, but for apps Google recommends 640×360. Google also created quite strict guidelines for creating apps, which may keep the environment homogeneous.
I’m working on use cases for small resolutions, because Glass is not the only device with such display. We’re hearing more about various wearable devices these days, like bracelets or watches (Pebble).
Public service
For a few years I had a vision to open QPDB for public, but not as a particle database, but more like a farm of databases. My inspiration was the concept of Wikia.com, where everyone can start his own wiki. I decided to do a similar thing, only with semantic/structured databases instead of wikis.
Crucial part is unfortunately my biggest weakness – to make it easy for the user. I began with stripping the user service and ultimately reduced offered functionality to the thinnest core. My target was to make it “just enough”. To keep the power in the backend and offer a bunch of presets, so to speak.
Application layers are: Databases > Classifications > Records (entities) > Attributes and relations.
In a database, user will be able to create classifications (in fact entity types, only available choice will be the name), attribute types (name, unit for numeric values, and data type) and relation types (name only).

Database classification management
Additionally, user can pick everything from preset templates, one set for home and the other for business. Templates can offer settings beyond the default available settings, like value range (e.g. 0-120 for age of a person).
For relations I dealt with unwanted entity types in suggest list, but how to get rid of them, when such thing is not available for this installation? Well, I made a little hack in the suggest algorithm, so when the name of relation type matches a name of any classification (entity type), only such entities are shown.
It’s the first public release of QB, aimed particularly to end users as content creators. QB had a public release two years ago, as Particle Database, but it was mainly to receive some feedback (which it did). Although I kinda like current style of QB, I feel this isn’t “it”.
I can imagine it’s far too off end-user’s expectations, may be confusing and hard to comprehend. But I’m still trying to think out of the box and I at least figured out some nifty stuff this time.
Setting the main focus
Even I call the Particle Database “The Database of Everything”, I had to set some boundaries and rules. I want to store there anything, what more than 100 different people can use and changes are not too often (better – never).
For weather it may be max/avg/min temperature for a day and month, but not precise temperature for specific date and time.
Similar situation is with currencies, we can update current exchange rate each day, but history has to go somewhere else. Table “ph” (particle history) is a good choice.
The best kind of data is precisely stated in Wikidi headline: places, people, products. We add parties.
Places are countries, further geographical/political divisions (counties, neighborhoods), cities as well as villages, streets, buildings, bridges, lakes, rivers and creeks, roads, railway routes, public transportation lines and stops/stations, points of interest (restaurants, various premises and services) etc. Anything you can assign fixed coordinates or a set of coordinates to.
People are obvious, but with humongous respect to privacy! If it’s not generally known, we don’t want to file it.
Products are anything you can buy in any kind of store. We prefer if it has a bar code (EAN). So it can be groceries, office supplies, furniture (IKEA is a great example), electronics, appliances, cars, gardening tools, fashion, brands etc.
Parties are groups of people, so it could be companies, politic parties, ethnic groups, religions etc.
Filling the database
There are three key components on a project like QetriX Particle Database: content, content and content.
My primary goal was to import all countries of the world with major/capital cities and all settlements in the Czech Republic with all main attributes into the database. It was quite easy task and it filled about 60 000 rows (about 13 500 entities). I mostly used just a spreadsheet (OOo Calc), because all I had to do was downloaded and consolidated some Excel files.
Then I found list of all streets in Prague, all first and last names in the Czech Republic, I gathered list of all mobile phone models, some aircrafts and cars, a lot of series with episodes and finally I got a list of almost all airports in the world. Altogether it was about 400 000 rows.
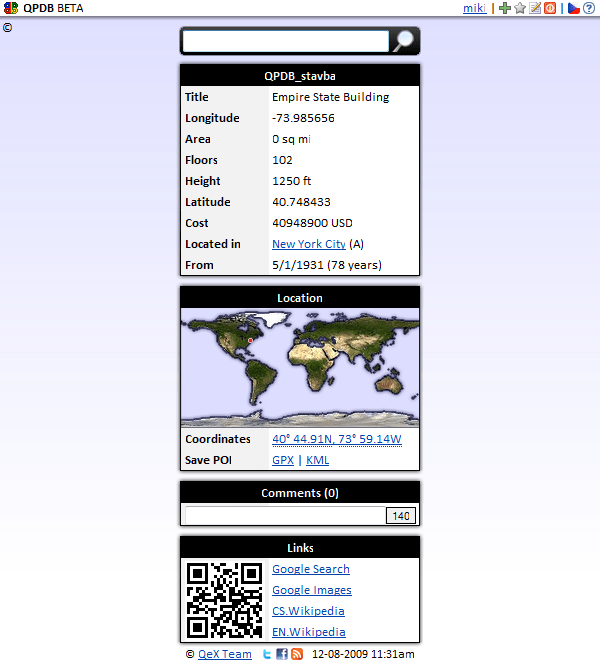
Empire State Building in the first public version of QB
I used custom made XML and TSV parsers. TSV is my favorite, because unlike commas, semicolons, pipes etc., tabs usually don't appear in data. Plus, when I copy-paste data thru clipboard from Calc to import front end, it's already as TSV – values separated by tabs. I had to create some custom made PHP scripts as well, for more complex or unevenly structured data sets.
One day I found some good keywords to find all kind of lists of Czech companies, so I put some of them into the database as well, along with some Czech POIs. But it was quite hard to find source of POIs without licence... There are great websites for POIs, but I don't steal. Anyway, 600 000 rows.
Then I found free to use sources of detailed structured data for particular aircrafts, like serial numbers, registrations, types, built dates etc. I love flying and I was always curious about the age of the aircraft I was about to embark. Not because I was scared, it was more about current state and what I can expect on board. Thanks to this I was able to create a simple app just for this :) 800 000 rows.
After that I had a lot of unfinished data sheets in Calc – taxonomy with animal species, administrative divisions and subdivisions of countries and cities, movies, songs etc. I was confident this is a good approach, because the data will be pure, complete to certain level and without any significant duplicities or mistakes.
I also defended this position in some disputation about amount of data the system provides. Even I had some previous experience with web crawlers and data parsers, I didn't expect I'll have to use it here (rather I didn't want to use it here). Boy, I was wrong! :)
The more I defended it, the more I thought about it and the more I understood this is the only way for larger number of data in database.
Finding a way
I understand everything in the world is somehow interconnected. I can buy a candy bar, manufactured by some company, whose HQ building has been opened the same day I graduated. If I want to cover all this by the data platform, the model must be really versatile.
I can imagine two approaches: Extensive and extensible database model, or universal data structure. Because of performance reasons I decided to go with the first option. My “proof of concept” was a lightweight encyclopedia for mobile devices, called “Kilopedia”, (max size of an article was 1 kB – hence the name).
In MySQL I created an “advanced database structure“, where each entity type has its own table. Every column (domain) in a table stored a value, as an attribute, or a foreign key (reference to a row in different table), as a relation. I had tables like “city”, “person”, “phone”, “airport”, “car”, “fruit”, etc.
User service worked closely with table structure and data types. When I rendered a form for data entry, I called DESCRIBE on the database table and used Field and Type columns to create HTML INPUT elements with appropriate data validations. When I wanted to add a new attribute to the entity type, I simply entered its name and system processed ALTER TABLE ADD COLUMN on background.
It worked like a charm; I was quite happy about it. It was nice, easy, fast, reliable and efficient. Until I noticed I have hundreds of tables in my schema, which is OK in general, but not for me :) All the time I was on a quest to create simple, clean and compact schema.
A downside was it would require some unpopular database denormalizations, maybe have a universal table with a lot of NULL columns. It would be nice to have some of the columns as a number, some as a varchar, datetime, bool etc.
I tried to design such table, but even before I started working on a prototype, I already knew this is a dead end. So I scratched the whole idea. But even a bad idea could move thinking towards the final solution, or you experience something, which you'll be able to use in the future.
And one more thing I didn't like about Kilopedia. Content of the articles was language dependent, without a chance to be automatically translated – like in Wikipedia, it would require creating separated text for each language, content may vary in different languages and every change would have to be done in all languages.
For me this was unacceptable and I knew the article part must go away. I wanted all changes to happen at once, in all languages and by a single modification. Only semantic values will do the trick.
Hello, world!
I've just started a blog and a wiki. Wiki is rather formal and serves as a documentation as well, while blog is going to be more informal and less technical. I plan to share my ideas, thoughts, future plans and current progress here, maybe some feature sneak peeks or backstage info.
Feel free to join the project on Facebook, Twitter or GitHub and stay tuned.
I kept writing blog posts here and there in the past, even knowing my readership usually consists just of me and some web crawlers :) But it helps me to sort thoughts, remind stuff and such. And even those posts may sound like product promotion, I write them mostly to try to inspire others and share my accomplishments, because I'd say I'm a bit nonconformist.
So, what so special em I talking about? Well, QetriX is a result of my long-term desire to create an ultimate yet simple semantic data platform. My niche are basically CRUD apps and after couple of years (and some dead ends) I created the final design.
Particle is an elementary data unit and a foundation of the platform. Every particle has certain properties, which allows to classify them into entities and specify their attributes or relations between them. In fact, it's a different approach to RDF, utilizing ER model (I created my own paradigm, but it was hard to explain the idea, so I moved towards better known stuff).
I started QetriX Particle Database even although there are quite a few online structured knowledge bases already, such as Freebase (incl. derived projects, like Wikidi), Yago, DBpedia, Wikipedia (esp. Wikidata) or even Wolfram|Alpha, but none of them allows or encourages to file insignificant entities, like local businesses, groceries etc. Or they were hard/unfriendly to use. I saw a hole on the market, which I was able to fill – even if it would be just for my own needs.
I'll go under the hood in some of my future posts; I don't want to shoot out all my ammo right away ;-)