Filling the database
There are three key components on a project like QetriX Particle Database: content, content and content.
My primary goal was to import all countries of the world with major/capital cities and all settlements in the Czech Republic with all main attributes into the database. It was quite easy task and it filled about 60 000 rows (about 13 500 entities). I mostly used just a spreadsheet (OOo Calc), because all I had to do was downloaded and consolidated some Excel files.
Then I found list of all streets in Prague, all first and last names in the Czech Republic, I gathered list of all mobile phone models, some aircrafts and cars, a lot of series with episodes and finally I got a list of almost all airports in the world. Altogether it was about 400 000 rows.
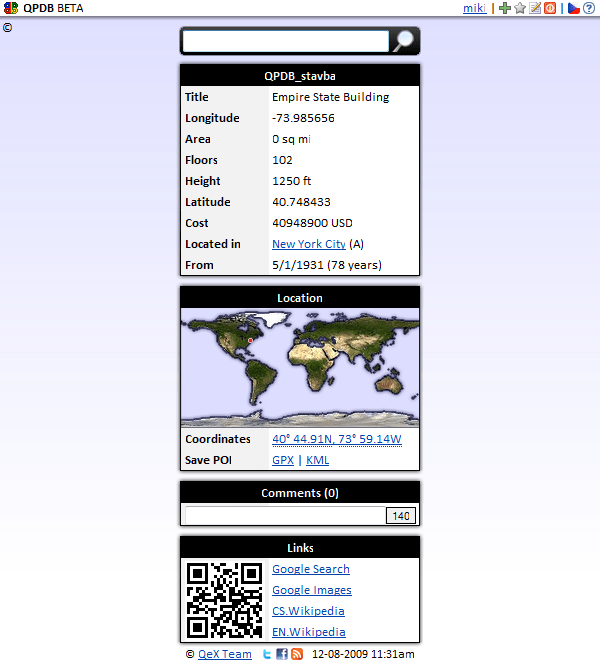
Empire State Building in the first public version of QB
I used custom made XML and TSV parsers. TSV is my favorite, because unlike commas, semicolons, pipes etc., tabs usually don't appear in data. Plus, when I copy-paste data thru clipboard from Calc to import front end, it's already as TSV – values separated by tabs. I had to create some custom made PHP scripts as well, for more complex or unevenly structured data sets.
One day I found some good keywords to find all kind of lists of Czech companies, so I put some of them into the database as well, along with some Czech POIs. But it was quite hard to find source of POIs without licence... There are great websites for POIs, but I don't steal. Anyway, 600 000 rows.
Then I found free to use sources of detailed structured data for particular aircrafts, like serial numbers, registrations, types, built dates etc. I love flying and I was always curious about the age of the aircraft I was about to embark. Not because I was scared, it was more about current state and what I can expect on board. Thanks to this I was able to create a simple app just for this :) 800 000 rows.
After that I had a lot of unfinished data sheets in Calc – taxonomy with animal species, administrative divisions and subdivisions of countries and cities, movies, songs etc. I was confident this is a good approach, because the data will be pure, complete to certain level and without any significant duplicities or mistakes.
I also defended this position in some disputation about amount of data the system provides. Even I had some previous experience with web crawlers and data parsers, I didn't expect I'll have to use it here (rather I didn't ''want'' to use it here). Boy, I was wrong! :)
The more I defended it, the more I thought about it and the more I understood this is the only way for larger number of data in database.
Prehistory of QetriX
QX Logo
In 2001 my best friend Pavel (Paul) came up with an idea to create an online discussion website / Internet forum and suggested name “QX”, because in Czech those two letters are only ones pronounced with three phonemes. In English it's much more common, there is also G, H, Y or British Z - /ˈzɛd/.
Anyway, in the meantime qx.cz domain became unavailable, so we eventually settled for QeX and registered qex.cz domain. It costed 1600 CZK = ~90 USD at the time, half of the amount was registration fee, and the other half was one-year prepayment (''such amount was several months' worth of our pooled pocket money, that's why we hesitated'').
1.x
QeX Logo
Pavel created the first version, using vlibTemplate engine, which he customized for QeX. It was mostly for us to learn PHP and MySQL. We wanted a little more, than just a discussion server, so we called QeX a “Multiportal”.
After signing in, user stepped into “Gate” – home page, where all important stuff resided, in fact it was sort of a "dashboard". From Gate he could go to list of “clubs” (chat rooms), or directly into particular club, where he discussed about a topic the club was created for.
Early logo of QX/QeX we used later as “helper” (like Clippy in MS Office) and appeared in what one day should be a learning center or help center. This logo and the following one were both entirely Pavel's work. Next and final logo contained “e”, as well, not just Q and X, and all those three letters were combined together into a head of hedgehog, or maybe a fox.

The only picture of QeX v1 I found, as a part of our promotion banner. (2001)
2.x
Version 2 was like a typical Internet forum. We had discussion clubs about various topics, where users can write their posts. Any user was eligible to create own club and manage it afterwards. Each club might contain a poll, a “home” (separated HTML text page attached to the club via link) and a “minihome” (HTML text above posts, limited in length).
Pavel introduced a concept of dashboard “sheets”. Service status, charts, daily info, news, weather, currency exchange rates... It was nice and small, sometimes even smaller, than the text itself with all the HTML tags around. And this way we were able to use gradients, and everything looked exactly alike in all web browsers – we're talking about IE5, IE6 and Netscape Navigator here! Everything was in table layout with very little of basic CSS.
Pavel also introduced “visit-cards”, containing all important info about the user, like his/her nickname, profile picture, current online status and timestamp of his/her last activity. Those cards were like a widget, which people can put on their websites.
On Gate there was also a bulletin board and system news. We had a tiny IFRAME, that reloaded every minute and checked for new stuff (like incoming mail or friends online) – there was no global support for XMLHttpRequest (later better known as AJAX) yet.

3.x
3rd version was released in 2003 and unlike previous 2 versions, this one was almost entirely my work. I recreated the whole engine from scratch, but still using the vlibTemplate with Pavel's customizations.
Instead of clubs it had “modules”, with various services. Module was just a shell around its data (=model) and service determined how to interpret the content (=view). We had services like section (list of child modules), discussion, monologue (form of discussion, where only owner can post), chat, gallery, game, plugin, book (one long post per page) etc.
Users could store desired posts to personal memos and post private messages to other users. We didn't need home/minihome anymore, because if required, user was able to create child text module for his/her discussion module with tight link in between.
System went from “clubs are managed by admin” to “modules are managed by the user-creator and his fellows”. User was able to customize the Gate as well, so it became like a dashboard of sort. We also opened modules for anonymous users, in read-only mode.
Modules were categorized into a tree. We had no tags or anything though, everything was managed by hand. But I figured out a smart method for drag'n'drop (in 2003 on web it was really something special), so it was quick'n'easy.
Browsers allowed to drag'n'drop hyperlinks into text fields, resulting of putting link's URL into it, so the method was simply a URL parser attached to onchange event of a text field, disguised as a checkbox.
Pavel's most significant idea later was to have a type for every piece of content, instead of having different services. It would allow us to have posts, pictures, games, polls, tables... not only in a single module, but in a single post as well!
But in 2004 it was for us quite hard to achieve, not only because of hardware issues, but mostly because of lack of our skills. And even now this would be challenging to do in an easy-to-use service.
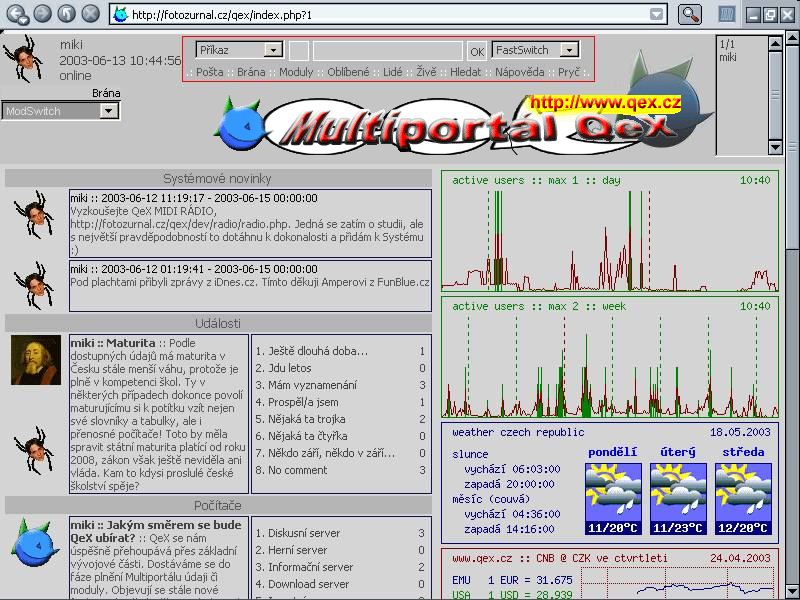

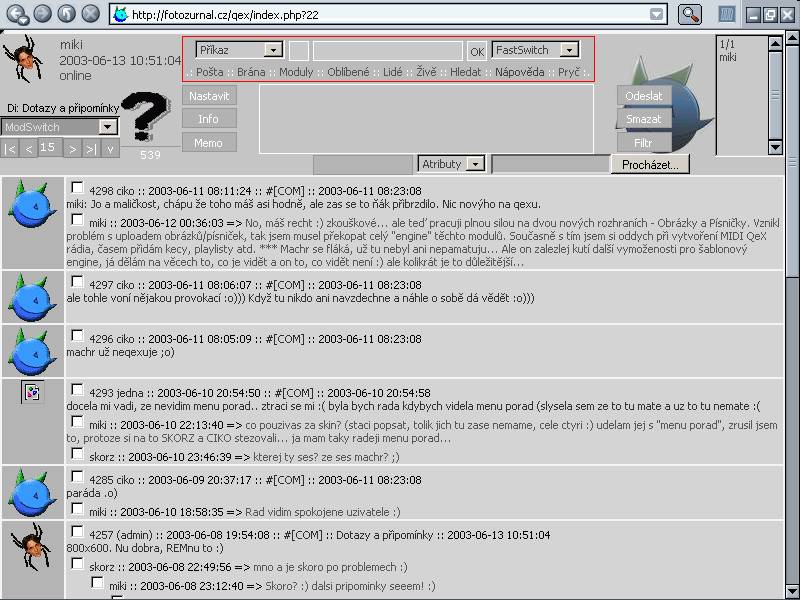
Version 3 had features, like in-browser games, where users could compete against each other (in pseudo real time or turn based) and beat others' high scores. With XHR still in its infancy, this was yet again achieved by an auto refreshing hidden iframe.
There was no Audio API in browsers of that time, but I created a small SWF for that. Thanks to it I was able to play logon/logoff sounds, incoming mail notifications etc.
In model, users and modules have been merged into modules. In database we kept table “users”, which contained auth info (username, password) and user's module ID.
We moved e-mail into “module” table, so users were able to insert content into module by sending an e-mail to module's e-mail address. Our hosting provider at that time was the only one I know about, that allowed assigning a PHP script to an e-mail address and process incoming e-mails.
As a side project we created “WiH” – “Where is He”. Because there were many discussion servers, like QeX, in order to be able to contact particular user as soon as possible, it would require you to know, on which server he/she is active right now.
Retrospectively I think v3.2 was the most advanced version of QeX ever made and influenced QetriX at most. Too bad Pavel eventually hold back in development, and I was ending just by myself. He was more underground, and I was more commercial, so he most likely realized we missed the right time for such underground project and lost his motivation.
Unfortunately, we experienced a major system outage with a database crash. It took some time to restore it and I decided it was time for another reengineering. We lost most of our users anyway.
4.x
In v4 I split major sections into 3rd level domains and created true multiportal – each of those domains acted like separate website with unique look. The module system concept was brilliant, there was no need to change it.
I have to admit there were some great new ideas for v4. I put homogenous data in modules into “windows” and enhanced terminology from “module” to “node”.
User had been able to specify permanent windows, block unwanted windows, define own windows or even call windows from other nodes. Windows had position and state, user was able e.g., to relocate or minimize them. I designed an amazing desktop-like service for our new “windows” concept.
For the first time the user service was much cleaner, no system lists or menus. Everything was up to the user, thanks to windows.
Aftermath
After the outage of v3 QeX had no regular users, so I kinda let the original idea die. I started to focus on for-profit projects, like my CMS, and kept alive only my personal website on QeX. And because the “www” domain was empty and abandoned, I created a web portfolio on it.
In the years after I used QeX in various different ways, but none of them went to reincarnate QeX. Nevertheless, I often realized our ideas for QeX are a goldmine, so from time to time I go thru our old text files and documents, like “ideas for v4”, and look for anything I'd be able to use today. Like my CMS used the module system and it moved to QetriX and Qedy as well.
I still think I may resurrect QeX one day again. After I graduated, I became an employee, so portfolio website is not needed any more and the domain is available for something new once again. The only downside is it's .cz and no other TLDs are available. So maybe something with just local ambitions.
DB schema on a diet
I had 9 tables just for data, out of 18 in total. That's 9 different data structures programmer/code would have to deal with during data manipulations (CRUD). That's quite different from what I see as universal.
It may be right from database development side, but ingenious ideas often come just because its author didn't know or care he's doing it wrong. And my layout was already quite wrong by storing numeric values as a text.
I decided to analyze table structure to find some similarities, allowing me to merge those similar tables. I was quite sure I'll find something in “type” tables, so I started with them. But it wasn't as easy as I thought.
At the moment it was just primary key and name, but I already had in my head I'd like to store more specific stuff in each of them, like data validations, max length or value type (text, numeric, date...) for attribs.
What bothered me more though were those three m:n tables – because I couldn't do anything about them, as each of them was unique. The only way was to merge table for entities, attribs and relations into one, but they were just too different!
One day I talked about it with my best friend and former co-developer Pavel. I also pointed out the potential, which we looked for when we were creating QeX (more about it later). He encouraged me to go ahead and try to merge those tables. So, I did. And the power of QetriX was born.
Semantic, baby!
OK, so I decided to create a semantic database. From relation database schema I had the basics – there's a row, row can have some columns and they may store some row's own values, or they can store a reference to some other row (in the same or different table).
Years later I determined the exact names I'll use for it: row = entity, column = attribute, reference = relation. And yes, any resemblance to ER model is purely intentional ;-)
My database model was quite obvious at this point: entity, attrib, relation, entity-attrib (m:n), entity-relation (m:n).

Then I started to think about what structure those tables should have. I started with “data”, tables – entity, attrib and relation.
First two columns were quite obvious – integer primary key (id) + tinyint some kind of “type”. Now I need something for data.
My first thought was: One column for text value + one for numeric value. And maybe one for datetime. Such model is good for performance and indexing, but I didn't like the code have to decide all the time where to put or look for a value and if I'd like to have one column always NULL. Single varchar column for value would be much better, but then I'll lose the performance advantage. But what about decimal numbers? Or dual values, like coordinates?
It felt like a Sophie's choice and after quite long thinking of all pros and cons I decided to sacrifice performance. I was going to store everything as a text, but the model will be pure.
Then I started to expand my thoughts about the whole schema little more. Relations should be able to contain attribs as well. So, another table for m:n relation emerges. And all rels, ents and attrs would have their own type as well... there we go, another 3 tables. That's 9 now and that's it!

Those tables are just for data, nothing else. Sure, pretty much everything in QetriX is “data”, but I needed more tables for specific purposes. Like translations, large text storage, secure file storage, activity log, change log, statistics, feedback or various caches. The schema grew big once again.
Finding a way
I understand everything in the world is somehow interconnected. I can buy a candy bar, manufactured by some company, whose HQ building has been opened the same day I graduated. If I want to cover all this by the data platform, the model must be really versatile.
I can imagine two approaches: Extensive and extensible database model, or universal data structure. Because of performance reasons I decided to go with the first option. My “proof of concept” was a lightweight encyclopedia for mobile devices, called “Kilopedia”, (max size of an article was 1 kB – hence the name).
In MySQL I created an “advanced database structure“, where each entity type has its own table. Every column (domain) in a table stored a value, as an attribute, or a foreign key (reference to a row in different table), as a relation. I had tables like “city”, “person”, “phone”, “airport”, “car”, “fruit”, etc.
User service worked closely with table structure and data types. When I rendered a form for data entry, I called DESCRIBE on the database table and used Field and Type columns to create HTML INPUT elements with appropriate data validations. When I wanted to add a new attribute to the entity type, I simply entered its name and system processed ALTER TABLE ADD COLUMN on background.
It worked like a charm; I was quite happy about it. It was nice, easy, fast, reliable and efficient. Until I noticed I have hundreds of tables in my schema, which is OK in general, but not for me :) All the time I was on a quest to create simple, clean and compact schema.
A downside was it would require some unpopular database denormalizations, maybe have a universal table with a lot of NULL columns. It would be nice to have some of the columns as a number, some as a varchar, datetime, bool etc.
I tried to design such table, but even before I started working on a prototype, I already knew this is a dead end. So I scratched the whole idea. But even a bad idea could move thinking towards the final solution, or you experience something, which you'll be able to use in the future.
And one more thing I didn't like about Kilopedia. Content of the articles was language dependent, without a chance to be automatically translated – like in Wikipedia, it would require creating separated text for each language, content may vary in different languages and every change would have to be done in all languages.
For me this was unacceptable and I knew the article part must go away. I wanted all changes to happen at once, in all languages and by a single modification. Only semantic values will do the trick.
Hello, world!
I've just started a blog and a wiki. Wiki is rather formal and serves as a documentation as well, while blog is going to be more informal and less technical. I plan to share my ideas, thoughts, future plans and current progress here, maybe some feature sneak peeks or backstage info.
Feel free to join the project on Facebook, Twitter or GitHub and stay tuned.
I kept writing blog posts here and there in the past, even knowing my readership usually consists just of me and some web crawlers :) But it helps me to sort thoughts, remind stuff and such. And even those posts may sound like product promotion, I write them mostly to try to inspire others and share my accomplishments, because I'd say I'm a bit nonconformist.
So, what so special em I talking about? Well, QetriX is a result of my long-term desire to create an ultimate yet simple semantic data platform. My niche are basically CRUD apps and after couple of years (and some dead ends) I created the final design.
Particle is an elementary data unit and a foundation of the platform. Every particle has certain properties, which allows to classify them into entities and specify their attributes or relations between them. In fact, it's a different approach to RDF, utilizing ER model (''I created my own paradigm, but it was hard to explain the idea, so I moved towards better known stuff'').
I started QetriX Particle Database even although there are quite a few online structured knowledge bases already, such as Freebase (incl. derived projects, like Wikidi), Yago, DBpedia, Wikipedia (esp. Wikidata) or even Wolfram|Alpha, but none of them allows or encourages to file insignificant entities, like local businesses, groceries etc. Or they were hard/unfriendly to use. I saw a hole on the market, which I was able to fill – even if it would be just for my own needs.
I'll go under the hood in some of my future posts; I don't want to shoot out all my ammo right away ;-)