Public service
For a few years I had a vision to open QPDB for public, but not as a particle database, but more like a farm of databases. My inspiration was the concept of Wikia.com, where everyone can start his own wiki. I decided to do a similar thing, only with semantic/structured databases instead of wikis.
Crucial part is unfortunately my biggest weakness – to make it easy for the user. I began with stripping the user service and ultimately reduced offered functionality to the thinnest core. My target was to make it “just enough”. To keep the power in the backend and offer a bunch of presets, so to speak.
Application layers are: Databases > Classifications > Records (entities) > Attributes and relations.
In a database, user will be able to create classifications (in fact entity types, only available choice will be the name), attribute types (name, unit for numeric values, and data type) and relation types (name only).

Database classification management
Additionally, user can pick everything from preset templates, one set for home and the other for business. Templates can offer settings beyond the default available settings, like value range (e.g. 0-120 for age of a person).
For relations I dealt with unwanted entity types in suggest list, but how to get rid of them, when such thing is not available for this installation? Well, I made a little hack in the suggest algorithm, so when the name of relation type matches a name of any classification (entity type), only such entities are shown.
It’s the first public release of QB, aimed particularly to end users as content creators. QB had a public release two years ago, as Particle Database, but it was mainly to receive some feedback (which it did). Although I kinda like current style of QB, I feel this isn’t “it”.
I can imagine it’s far too off end-user’s expectations, may be confusing and hard to comprehend. But I’m still trying to think out of the box and I at least figured out some nifty stuff this time.
Cool Events
''I tried to came up with a cool title for this hot spring day, so I hope this is cool enough ;-)''
Event is triggered on a specific occasion. It can be specific timestamp (wildcards are possible) or any kind of manipulation with entity/attribute/relation type or even specific entity/attribute/relation.
Main purpose of an event is to launch associated script (set of commands) in a Q scripting language, described in the previous blog post.
My first hunger for events was in my early project (2007), where everything was hardcoded. And except nobody has an idea how it actually works, it was a real pain to fix bugs in it. For the next version I designed (in my head) a way, how to make it editable. But because I had no customer for the change and I was unable to make it my personal project, the idea stayed just in my head.
I don’t need any bells or whistles, I just need a tool for designing a list of consecutive commands and some minor evaluating on the way. It’s like “when ''this'', do ''that''”.
For timing events there will be a cron or a job (mostly every day or every hour), for data manipulation there will be some hooks hardcoded into CRUD methods. Nevertheless, the system has to be detachable, because I want to have system of independent layers (as I hate to execute unnecessary code over and over again).
And what is so cool about those events? I won’t have to hardcode specific behavior any more, I’ll just set a trigger (event) and write some commands to be executed. And that pays off.
Q for events
Everything in QetriX is somehow unique or innovative. From my previous projects I knew I would need a simple scripting. I tried LUA, but it was too complex. I tried JavaScript, but it was even more complex :)
In my mind I already had a concept of simple scripting language. Every line will contain one command and, like in Assembler, there will be a keyword first, then arguments separated by space. I didn’t care about spaces in text, because only language keywords would be allowed and they won’t contain spaces anyway.
I call this language “Q”, because in English it has the same pronunciation as “Cue” and it’s meaning is similar to purpose of the language – to trigger an action.
From general perspective it’s a bad language, because it has wildly disputed “goto” command. And even worse – “goto” here is the only command for structure, as there are no blocks (like curly braces in C) and all functions has to be coded in advance in platform’s source code. From Q you can only call them with arguments and retrieve their return value.
There are no variables in Q, the result of each command is stored under a number of the line, where the command is. When you need the value, you can simply recall it by using hash and number of the line, e.g. #5 to get a value from the fifth line.
I'm aware this approach wastes a lot of memory, but I don't think it will cause any major problems. It's not designed to be anything huge and there could be further optimizations, like parser may get all the references beforehand and do not store values for never queried lines.
Now let me show you how to code (comments are not part of the code):
- add 5 4 // Calculates 5+4 and stores the result (9) into line #1
- sqrt #1 // Calculates square root of the result from line 1 (=9)
The output of the script above is 3. You can get the output by either using a “return” call and specify the value (constant or line value) as its parameter, or by finishing a last line of script, where output will be a value of the last line’s value. Second choice is our case, final output will be a value of the 2nd line.
The only thing I don’t like (but I don’t see any other option, so I dealt with it) are conditions; IF statements, so to speak. Because it technically consists of two parts – condition and then/else branches, I had to split it onto two lines. In the first one I eval the condition (and store true/false result), the second one is if-goto statement. There is no else branch, because if the condition is false, the parser goes to the next line (which is, in fact, the else branch).
I thought about more complex “if” statement, but only this way you can use multiple conditions clearly. The only ''hack'' is, that “if” is always if-goto, it’s NOT an if-command, because it would violate the single-line-single-command concept.
There is a major catch for editing the code though, when number of lines changes due to add/remove lines in the middle of the code. For this reason there is a smart code editor “out of the box”, which also draws a diagram of the source code (little help to manage all those gotos) and provides inline help for each command and it’s arguments. It also allows to run the code and display a step trace.
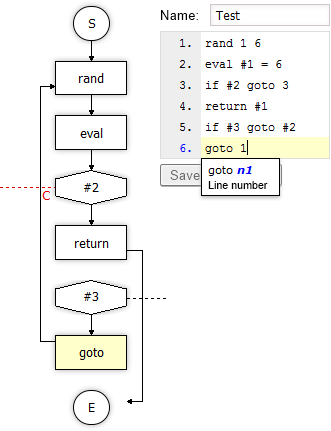
QetriX Q Code Editor
The best usage though is to define actions between two states in a work flow. In QetriX you can define events, as a starting point for launching Q script. Events are fired in specific occasion, but I’ll write about it next time. For more info about Q please visit our wiki.
Flat File Database
Because I don’t want excessive database use, I decided for FREE version of QetriX to use flat files as data storage.
Flat files are plain text files, where entries (rows) are delimited by Enter (Line Feed, or \n in this case) and values on each rows are delimited by a special characters (CSV uses comma or semicolon, I prefer Tabs).
I noticed I was often quite lazy when writing data retrievals from database and instead of abstraction I used a lot of SQL code. I know this is a bad habit and I should use abstraction or ORM, but in this stage I prefer quickness over a nice’n’clean code (and I’m still balancing the most suitable object structure for datastore at the moment). I’m going to review the whole thing anyways. For this reason I use quite a lot inline CSS in HTML as well, it helps me to organize my CSS classes better afterwards.
Knowing this, I created a SQL parser for each of CRUD queries using regular expressions. Then I converted results into arrays and processed them over data. The most challenging one was a WHERE clause, which currently supports only AND operator (not OR). In all cases I consider the first column as an auto-increment primary key.
Aside I created routines for data retrieval and saving, I used multidimensional associative array for in-memory data storage. Because I wanted to keep the each table in a single file and for purpose of QetriX I don’t care about data types, first line of each file will contain tab-separated column names. Later I found out that I’ll be able to put some additional info about each column here too. Because column name mostly doesn’t contain a space (in my case never), I can use space as a 2nd level separator. This way I can define primary key, default value (incl. auto increment, but with limitation I can’t use spaces in strings) and even data types.
All data modifications I make on in-memory data and store changed structure into a file afterwards. If I want to modify anything, the use case is: load data > make changes > save data. There are some application logic for performance improvements, obviously.
At first I was somehow distrustful, because it worked weirdly good :) But later I discovered this was foul and gained a trust. It works really good, it’s very simple and reliable.
As everything around QetriX, this solution didn’t aim to completely replace database. It lacks most features of e.g. MySQL, it’s just a workaround for purposes I don’t want to use database and target data scope is rather small. Perfect for FREE account, where user can store 5 databases with 5 classifications and 5 attribute/relation types for each classification.
Setting the main focus
Even I call the Particle Database “The Database of Everything”, I had to set some boundaries and rules. I want to store there anything, what more than 100 different people can use and changes are not too often (better – never).
For weather it may be max/avg/min temperature for a day and month, but not precise temperature for specific date and time.
Similar situation is with currencies, we can update current exchange rate each day, but history has to go somewhere else. Table “ph” (particle history) is a good choice.
The best kind of data is precisely stated in Wikidi headline: places, people, products. We add parties.
Places are countries, further geographical/political divisions (counties, neighborhoods), cities as well as villages, streets, buildings, bridges, lakes, rivers and creeks, roads, railway routes, public transportation lines and stops/stations, points of interest (restaurants, various premises and services) etc. Anything you can assign fixed coordinates or a set of coordinates to.
People are obvious, but with humongous respect to privacy! If it’s not generally known, we don’t want to file it.
Products are anything you can buy in any kind of store. We prefer if it has a bar code (EAN). So it can be groceries, office supplies, furniture (IKEA is a great example), electronics, appliances, cars, gardening tools, fashion, brands etc.
Parties are groups of people, so it could be companies, politic parties, ethnic groups, religions etc.