iPad as a Windows display
I don't have second LCD at home.
I've always had a tablet laying around, either ancient iPad 2 in the office, or my mother-in-law's old Android tablet, which I use when baking or cooking to view the recipe, because I don't mind getting it dirty.
When I finally decided to buy myself a digital piano, I kinda like Synthesia. I originally purchased a license on my iPad, but later I found out if I'd purchase it on the website, it will work on all devices! I was kinda mad at myself I didn't do proper “due diligence” and it leželo mi to v hlavě tak dlouho, až jsem se rozhodl koupit i tu webovou licenci.
Little while later I learned, that the “Synthesia LLC” company is in fact just a single developer. Now I'm glad I supported him.
smart home addition
acts like secondary display, you can position it in settings. connects either via cable or via wifi, which basically means you can access the PC anywhere in the range. It opens a whole lot of new use cases!
added touch - testing qard! It doesnt support mouse on iPad, but it does support keyboard, so I can use Magic Keyboard connected to the iPad and thru the app write on my PC.
Speaking of mouse, invert scrolling
Let's Qard
…
describe insides how to make game in Qard
Experiences and upgrades during GemTube development
Arctica (Svalbard)
Our trip to Antarctica was fantastic and the very special occasion we went there for repeated once again in the summer as well, so a thought of visiting both polar regions just a few months apart really intrigued us. This time only for a few days though, because 99 % of Arctic tours are “just” around Svalbard anyway and it's quite pricy there.
To our surprise my wife found a 6 day trip with 4 day expedition cruise, similar to the Antarctic one (yay!), costing as much as just accommodation in Longyearbyen with guided day trips for the same duration. It was no brainer, we booked it matter of hours.
Fixed dates made airfare booking much simpler. I found 4-leg itinerary, via Brussels, Oslo and Tromsø, with Business Class for just €20 extra! But the flight home wasn't ideal, so we went for the much cheaper 2-leg option, with almost a full day in Oslo.

Home-smoked seal, reindeer and whale.
It felt kinda weird to just hop on a plane and go way past the Arctic Circle – no all day flight, no Drake Passage... Per usual, we didn't hesitate to taste the local fauna, even though some items on the menu can be controversial.
To my glee the expedition cruise was really similar to the Antarctic one, the weather and scenery as well, although “low-grade” – smaller icebergs, fewer animals (oops, did we ate them all?), but more colorful surroundings.
Because, to my very surprise, I didn't mind the polar plunge in the Southern Ocean, I was ready to repeat it. But this time as a polar swim – going to the icy water from a shore. Yikes!
I confirmed my previous experience, that I need to endure first ~20 seconds of big discomfort, but after that I can stay in the water for minutes. The only downside was we both injured our feet from stomping on stones while rushing into the 6 °C / 43 °F water.

Smeerenburg Glacier over Bjørnfjorden
There was a Wi-Fi on the ship and I was curious to try their mobile app, that works only while connected to the on-board Wi-Fi, but it's apparently only for the bigger ships, because it didn't work on this particular expedition ship.
GSM signal kms from Longyearbyen, EU roaming, radio silence in Ny Alesund
logbook in Canva
Memory leaks in JS
Memory leaks in JavaScript can be a common issue for developers, and they can have a significant impact on the performance and stability of web applications. In this article, we will explore what memory leaks are, how they occur in JavaScript, and techniques to detect and prevent them.
Understanding Memory Leaks
A memory leak occurs when a program allocates memory but fails to release it when it is no longer needed. In JavaScript, which is a garbage-collected language, memory management is generally handled automatically by the browser's JavaScript engine. However, developers can still inadvertently cause memory leaks through their code.
Common scenarios leading to memory leaks in JavaScript include:
- *Unintentional Closures*: Closures are powerful constructs in JavaScript but can also lead to memory leaks if not used carefully. When a function references variables from an outer scope, it keeps a reference to those variables, preventing them from being garbage-collected.
- *Forgotten HTMLElement references*
- *Forgotten Event Listeners*: Registering event listeners is a common practice in web development. If you forget to remove an event listener when it's no longer needed, the associated objects won't be garbage-collected, leading to memory leaks.
- *Global Variables*: Variables declared in the global scope remain in memory for the entire lifetime of the web page. If you forget to clean up global variables, they can cause memory leaks.
- *Circular References*: Objects that reference each other in a circular manner can't be garbage-collected, as they still have references to them.
Detecting Memory Leaks
Detecting memory leaks can be a challenging task, but there are tools and techniques that can help:
- *Browser DevTools*: Modern browsers offer memory profiling tools that allow you to take snapshots of the memory usage and compare them to find memory leaks. Chrome DevTools, for instance, has a "Memory" tab that helps analyze memory consumption.
- *Heap Snapshots*: You can take heap snapshots in the browser's developer tools to see which objects are consuming memory and identify any unexpected long-lived objects.
- *Memory Leak Detection Libraries*: There are JavaScript libraries like leakage and why-did-you-render that can help detect memory leaks in your code by monitoring object creation and destruction.
Preventing Memory Leaks
Preventing memory leaks is often more effective than trying to fix them later. Here are some strategies to help you avoid memory leaks:
- *Remove Event Listeners*: Always remove event listeners when they are no longer needed. You can use methods like removeEventListener to ensure that DOM elements can be properly garbage-collected.
- *Scope Management*: Be mindful of closures and function scopes. Avoid keeping references to outer variables that are no longer needed. When you're done with a reference, set it to null.
- *Use WeakMap and WeakSet*: These data structures can be used to store weak references to objects. Weak references won't prevent objects from being garbage-collected when no other references exist.
- *Global Variables*: Minimize the use of global variables. When you do use them, be sure to clean up after your application no longer needs them.
- *Testing and Profiling*: Regularly test your application using memory profiling tools. By catching memory leaks early, you can address them before they become major issues.
Conclusion
Memory leaks in JavaScript can have a detrimental impact on the performance and reliability of your web applications. It's crucial to be aware of the common causes of memory leaks and to use the available tools and best practices to detect and prevent them. By following these guidelines, you can create more efficient and stable JavaScript applications.
Is Twitter X-ing?
The Twitter API finally got shot down.
These three tiers include a bare-bone free level mostly meant for content posting bots, a $100 per month basic level and a costly enterprise level. None suitable for my purpose.
Free: Write-only access to Twitter, with the ability to post 1,500 tweets per month is still free, although this tier wasn't even originally considered.
Basic: Twitter’s new “Basic” tier will cost $100 per month and will enable you to post up to 3,000 tweets per month at the user level, or 50,000 tweets at the app level. The read limit for this tier will be 10,000 tweets per month.
Pro (added later): $5,000 per month, get 1M Tweet and post 100k per app.
Enterprise: This level is for big platforms that make significant use of the Twitter API and will cost up to $42,000 per month.
Academics are being given free access to for noncommercial purposes.
Since taking over the social media network, Elon Musk has focused on cutting costs and boosting revenue, firing thousands of employees and doubling down on the company’s paid Twitter Blue subscription service. Musk justified the API changes by saying the free service was “being abused badly” by “bot scammers & opinion manipulators.”
Still baking
It's been two years and I still bake, now more than ever – with the ongoing inflation some items went up 20 %, so I'm using my wisely created stockpile of cheap flour and olive oil, and we try to use the electric oven for as much items at once as feasible, because it takes 10-15 minutes to heat it up.
While my wife was out skiing, I enjoyed some alone time and tried to bake a pizza. To my surprise it went really well and the dough was delicious! However, regular oven is not hot enough for pizza, the best you can do is to preheat it to the max (250°C / 480°F in my case), including the baking tray, and bake it nearest the top heating element (for just 7 minutes).

Salami mozarella pizza with green olives
As I mentioned, we regularly eat savory pastry with something (cheese in my case) for dinner, as lunch is the main meal of the day. So now I bake twice a week, on Monday and Friday. I found a way to bake as soon as possible after we return home from work, using retarded dough.
I prepare the dough in the evening and let it proof. Then I shape the rolls and stuff, put them covered in cling film to the fridge till the next evening. Then I take them out of the fridge to heat up a bit, preheat the oven to 230 °C / 450 °F and bake it for 18 minutes.

Buns, bread rolls and my signature GridBites with caraway
poppy seed filling non cooked using yogurt, with plum spread (povidla)

Poppy seed star
HJSON in PHP
HJSON in JS... provide PHP code. Not complete HJSON, but most of it.
Dynamic document template
Legito
Debugging in JavaScript
stack in console.debug: { at: Error().stack.substring(6).split("\n") }
filter in devtools console still triggers console.debug
custom console
mobile: In Chrome 73, we added the chrome://inspect page which locally displays JavaScript logs to assist in debugging webpages
Also Safari webinspector with Mac: https://help.remo.co/en/support/solutions/articles/63000251570-how-to-activate-the-iphone-debug-console-or-web-inspector-
Debugging in Qard
canvas shadow, custom console, debug info printed on screen, FPS and UPS
Reactivity
Reactivity for DOM updates using e.g. Signals
Cloned templates for DOM rendering. Security issues using innerHTML.
Using APIs like <template> and Proxy: template.content.cloneNode(true)
Error handling in PHP
asdfasd
- $self = $this; // To use $this in closures
- set_error_handler(function ($en, $es, $ef, $el) use ($self) {
- $self->error("Error #".$en, $es." (".$ef.":".$el.")");
- });
- set_exception_handler(function ($ex) use ($self) {
- $self->error(get_class($ex), $ex->getMessage()." in ".$ex->getFile()." on line ".$ex->getLine(), $ex->getTrace());
- });
asdf
- private function error(string $heading, string $message = "", array $trace = null) { http_response_code(500); if ($_SERVER["HTTP_ACCEPT"] === "application/json") {
- exit($this->json([
- "status" => "error",
- "message" => $message,
- "trace" => $trace ?? debug_backtrace(0)
- ]));
- }
- $sTrace = ""; foreach ($trace ?? debug_backtrace(0) as $i => $exl) {
- if (isset($exl["file"])) {
- $sTrace .= "\n#".$i." ".$exl["file"]."(".$exl["line"]."): ".($exl["type"] ?? "").$exl["function"];
- }
- } exit("<!DOCTYPE html><html lang=\"en\"><head><meta charset=\"utf-8\"><title>".$heading."</title><link rel=\"stylesheet\" href=\"error.css\"></head><body><h1>".$heading."</h1><p>".$message."</p><pre>".$sTrace."</pre></body></html>"); }
The produced trace string could look like this:
- #0 D:\Dev\PHP\quid\quid.php(170): ->error #1 D:\Dev\PHP\quid\tests\trace.php(99): ->{closure} #2 D:\Dev\PHP\quid\quid.php(239): ->test #3 D:\Dev\PHP\quid\quid.php(72): ->__construct
source code using $lines = file($errFile), I did further optimizations for certain scenarios, like with PDOException I don't need to see the code for get/set method in the PDO service, but rather where the query has been constructed. For this I simply iterate over stack trace and show first script, that differs from the last one. This obviously wouldn't work properly in other scenarios, so you should adjust the behavior to your situation.
asdf
<wbr> HTML element for breaking long paths on slashes
asdf
XDebug, breakpoints
- if ($this->debug && function_exists("xdebug_break")) {
- ("xdebug_break")(); // Intelephpsense error workaround
- }
doesn't work properly in set_error_handler, because the calls stacks starts there, not in the code that threw the exception.
asdf
Use master try-catch and try not use local, especially if it's silent. You will probably never know about the problem. If you use local, you should rethrow the exception.
InputManager
Pretty much every game engine is using some kind of input manager to translate sensor inputs into game actions, especially because you can use a multitude of input devices and modes.
multiplayer on single device, key mapping to action, scopes (in car, on foot...), player assignment to named actions
keyboard
pointer mouse
controller
mobile - gyro, multitouch...
Are you REALLY debugging what you think?
Last year I wrote about making sure you're editing the correct file. Now I have a similar topic.
It happened to me, that I was mentally expecting some value, so I was baffled why the code doesn't work. It was a numeric code, so it wasn't apparent that actually the code did what it supposed to do (duh!) and I was in fact expecting some other code, which wasn't the one I was getting.
Sandpit
Sometimes it may be hard to grasp concepts I used for QetriX. You can imagine your application as a sandpit (or “sandbox”, in the original meaning).
Sandpit: Module
Water from a garden hose: Service
Mud pie: Converter
Leaf, petal...: Service?
Sand: Output format (clay, mud...)
Link preload × prefetch
rel="preload" loads a resource early for the current document before the body is parsed, potentially saving overall loading time.
As a hint with a lower priority, rel="prefetch" caches a resource for the next navigation after the current document has been loaded.
Lorem ipsum dolor sit amet.
- <link rel="prefetch" herf="URL">
vs
- <link rel="preload" href="URL" as="MIME_TYPE">
preload is a declarative fetch, allowing you to force the browser to make a request for a resource without blocking the document’s onload event.
Prefetch is a hint to the browser that a resource might be needed, but delegates deciding whether and when loading it is a good idea or not to the browser.
preload
<link rel="preload"> tells the browser to download and cache a resource (like a script or a stylesheet) as soon as possible. It’s helpful when you need that resource a few seconds after loading the page, and you want to speed it up.
The browser doesn’t do anything with the resource after downloading it. Scripts aren’t executed, stylesheets aren’t applied. It’s just cached – so that when something else needs it, it’s available immediately.
prefetch
<link rel="prefetch"> asks the browser to download and cache a resource (like, a script or a stylesheet) in the background. The download happens with a low priority, so it doesn’t interfere with more important resources. It’s helpful when you know you’ll need that resource on a subsequent page, and you want to cache it ahead of time.
The browser doesn’t do anything with the resource after downloading it. Scripts aren’t executed, stylesheets aren’t applied. It’s just cached – so that when something else needs it, it’s available immediately.
Autumn cleanup
I noticed some concepts in Qedy ain't right. For instance, I always perceived Modal window as a separate entity, but in fact it's just bit more complicated QView. This also once again confirms, that my choice of just four component types (elem, form, list, view) is indeed sufficient.
Similar problem was with various frontend perks, like content prefetching or smooth scrolling. I added prefetch to an ordinary QList as f_prefetch feature and I created some extensions (“plugins”) for QView_Page.
HTTP routing
http://nikic.github.io/2014/02/18/Fast-request-routing-using-regular-expressions.html
https://github.com/nikic/FastRoute
https://benhoyt.com/writings/go-routing/
You have several options, how to route HTTP requests. My habit is to find the fastest way, but it's not needed here, because the router is called only once on URL change.
Table
Loop through pre-compiled regexes or patterns and pass matches using the request context
- router.addRoute(httpMethod, "a/(*.)/c", routeHandler),
Or use directly the HTTP method:
- router.get("a/(*.)/c", routeHandler);
Switch
A switch statement with cases that call a regex-based match() helper which scans path parameters into variables.
Similar to regex match, but using a simple pattern matching function instead of regexes. It's not that powerful, but you will mostly need “anything” wildcard for a path part anyway.
- case httpMethod == "GET" && routeRegexPattern.match("a/(*.)/c"):
- return routeHandler();
Split
Split the path on / and then switch on the contents of the path segments
- case httpMethod == "GET" && p[0] == "a" && p[1] == "b":
- return routeHandler();
Shift
Basically delegates the route matching to the module, according to the first path part. For a/b/c path the router will call an “a” module, pass him [b,c] and don't care any more.
Web icons
You have several options when it comes to icons on a web. The oldest way is to use images (GIF, later PNG), but they may look blurry on today's high DPI displays. You can use SVG, which is great, scales great, but may become CPU heavy and are harder to recolor on hover events. And then you have font icons.
Typicons
Microns
Icomoon
Font Awesome 3
Font Awesome 4
Behavior diagrams
Behavioral diagrams basically capture the dynamic aspect of a system. Dynamic aspect can be further described as the changing/moving parts of a system.
Behavior diagrams emphasize what must happen in the system being modeled. Since behavior diagrams illustrate the behavior of a system, they are used extensively to describe the functionality of software systems. As an example, the activity diagram describes the business and operational step-by-step activities of the components in a system.
Activity Diagrams
Activity diagram describes the flow of control in a system. It consists of activities and links. The flow can be sequential, concurrent, or branched.
Activities are nothing but the functions of a system. Numbers of activity diagrams are prepared to capture the entire flow in a system.
Activity diagrams are used to visualize the flow of controls in a system. This is prepared to have an idea of how the system will work when executed.
Use Case Diagrams
Use case diagrams are a set of use cases, actors, and their relationships. They represent the use case view of a system.
A use case represents a particular functionality of a system. Hence, use case diagram is used to describe the relationships among the functionalities and their internal/external controllers. These controllers are known as actors.
Flowchart
asdf
Swimlane Flowchart
asdf
Interaction diagrams
Interaction diagrams, a subset of behavior diagrams, emphasize the flow of control and data among the things in the system being modeled. For example, the sequence diagram shows how objects communicate with each other regarding a sequence of messages.
Sequence diagram
Ideal for visualizing web services. A sequence diagram is an interaction diagram. From the name, it is clear that the diagram deals with some sequences, which are the sequence of messages flowing from one object to another.
Interaction among the components of a system is very important from implementation and execution perspective. Sequence diagram is used to visualize the sequence of calls in a system to perform a specific functionality.
There are lifelines and stuff.
Communication diagram
JavaScript Framework Mk. III
If I find reengineering favorable, I usually go for it. Therefore major versions with breaking changes appear fairly quickly in the beginning of a new software product, allowing me to stabilize the API as soon as possible.
On the other hand, most changes are in QedyJS, so unfortunately almost none of the current improvements will go open source.
Scopes. Multiple modules at once, scope is passed with the component, which is no problem in most cases. But it's a little annoying, since I decided to have no cirucular references, which means a component can't contain scope object and therefore I have to pass component and scope separately in two parameters. And for the rest you must specify the scope, which is also annoying, but also necessary.
Speaking of scopes, I reimagined JavaScript scopes as well. Now module methods have direct access to the scope via this and because I decided to “trust” converters, they have now direct access to components and therefore are able to modify them. It makes a lot of things much easier and more streamlined.
I waited with a release many months, to have full functionality right from the start. Nothing was postponed (like datastores in Mk. II), because that's what bit me in the butt in the past the most.
Found even more great articles and talks about JS performance and did tremendous amount of micro optimizations in the code, especially in loops, where it makes sense the most. Some (if not most) of them are probably unnecessary, but I'm a performance freak, so it feels good to have 'em all :-)
Got rid of domLinks, now links are bundled with the component. The same applies for items and data-realted logic (e.g. sorting and filtering) were moved from components to datastores.
Some of original designs are great and in fact some of them even goes back to Mk. I. And don't let me start with the whole concept of QetriX, I must admin it makes me proud the core basics I established over a decade ago still works perfectly.
Navigator
Browsers and especially Chromium based ones offers a lot of information about the device it's running on in various APIs. They are great if you want to tailor the experience for your users.
Some of such APIs are in Navigator service, accessible as read-only object from window.navigator property.
navigator.connection: .effectiveType (how fast), .saveData (data saver preference)
navigator.deviceMemory: reducing memory consumption
navigator.hardwareConcurrency: limit CPU intensive logic and effects
Those APIs also could be abused. There's a rumor one Booking site used now deprecated Battery Status API to crank up prices when your Android phone was running low on juice and therefore you probably didn't have much time to think and compare.
CORS and CSP
In recent years browser manufacturers added an additional security checks for third party content, in a form of headers or META tags.
CORS (Cross-Origin Resource Sharing) is telling the browser it can read data even if it's in different origin. You can get around it using a CORS Proxy.
CSP (Content Security Policy) battles XSS (cross site scripting) and packet sniffing attacks, and exists in three versions. The first requires to specify a white-list of allowed sources in Content-Security-Policy header, which often led to enabling all of them for convenience. The second introduced a nonce, and the third is the best, but not yet widely supported.
xx
I had a little more time, so instead doing just incremental changes I was able to go knee-deep into some of those excremental ones :-)
QuacFeeds
RSS, RDF, Atom easily, not inventing wheel. It's similar to each other, so I used XDocument for that with ease.
Every feed item holds a “feed” object, containing basic info about the feed, because in one timeline there are multiple feeds.
As a storage I used serialization, until it became unbearable and I'll do it properly using SQLite database.
QuacTweetsRead
Register as Dev on Twitter website.
For starters I used a nice tutorial by Danny Tuppeny for simple Twitter posting and it really worked right away. But I abandoned his solution for one based on TinyTwitter, which I still had to modify heavily.
For example, it's quite old and therefore doesn't support 280 char tweets. I had to add tweet_mode=extended to API call and then in JSON response use full_text instead of text.
Speaking of JSON, for Qip I used heavily modified custom JSON library, even there's the popular Json.NET from Newtonsoft. It's based on per-character loop and I don't think there's much faster approach how to parse it.
I customized it to accept comments and commas after the last element or property (in a JSON5 manner). For viewing I used open source JSON Viewer by Eyal Post.
Problem datetime created_at thanks to solution:
```
DateTime createdAt = DateTime.ParseExact(tweet["created_at"],
"ddd MMM dd HH:mm:ss +ffff yyyy", new System.Globalization.CultureInfo("en-US"));
```
asdf
QuacIcons
…asdf IconsDownload
RSS or favicon
Bitmap as PNG or ICO to PNG
Quac icon as dynamic bitmap.
Custom Quac icons, that gives users a freedom to use whatever icon they please.
Pricing decisions
Price per version
Price for product and all updates
Subscription with perpetual license
Subscription
Paid extensions: microtransactions, in-app purchases, DLC (Trainz!)
D1ck move, but somewhat effective: force users to buy tokens in bulk, but don't allow them to spend them all. Like force them to buy minimum of 200 tokens, but your service costs 130 tokens a month. With this pricing, they'd need 19(!) months to get all their money's worth. It's like on concerts/events/food festivals, where catering is available only using their custom currency.
Commercialization
Open Source (various licenses, donations)
Source Available
Free
Free for personal use
Free Demo
Free Trial
Shareware
Paid. More on that next time.
…
StackOverflow Data Model
I often look for inspiration at large open projects, like Moodle, WordPress or PrestaShop. Some of them have great ideas, some of them use proven concepts and some of them... just work, despite their design :-)
This time I looked at StackOverflow, which is visited by some 50M users each month, so their solution must be really robust.
Emphasizes Microsoft technologies, with a focus on performance, scalability, and reliability: ASP.NET Core as its web framework for the backend, Microsoft SQL Server as its primary database, Redis for caching, Elasticsearch for search, Docker for containerization, TeamCity for its continuous integration and deployment, Git for version control and hosted on Azure.
SVG, Sometimes Verbose Gibberish
For icons and glyphs I've always preferred webfonts, because they're easier to work with and has much lower impact on CPU. But they're not easy to create, fortunately there are services like Fontello, that allows to pick only what I need.
Inline SVG in CSS
- background-image: url('data:image/svg+xml;utf8,<svg height="16" version="1.1" viewBox="0 0 48 48" width="16" height="16">...</svg>');
no easy :hover color change
Mismatched markup, unnecessary namespaces, ballast metadata from editors, empty <g> elements etc.
Editing by hand, simple HTML editor
Tracking precision
problem with jiggering about, making tons of unuseful logs
precision < distance
Inverse square root
https://pastebin.com/4Afm45AH
https://en.wikipedia.org/wiki/Fast_inverse_square_root
www.beyond3d.com/content/articles/8/ www.beyond3d.com/content/articles/8/www.beyond3d.com/content/articles/15/ www.beyond3d.com/content/articles/15/www.lomont.org/Math/Papers/2003/InvSqrt.pdf www.lomont.org/Math/Papers/2003/InvSqrt.pdfbetterexplained.com/articles/understanding-quakes-fast-inverse-square-root/betterexplained.com/articles/understanding-quakes-fast-inverse-square-root/
Even I still adore Data Particles I “invented” almost 10 years ago, without proper tools (I struggle to create) it's quite hard to manage the data. I encounter it from time to time when I need to fix some order in our intranet app.
So for QB I decided to move from Data Particles to JSON structure I created for Qedy. It suits the purpose rather well and I can improve it to be mutually beneficial.
- float Q_rsqrt(float number)
- {
- long i;
- float x2, y;
- const float threehalfs = 1.5F; x2 = number * 0.5F; y = number; i = *(long *) &y; // evil floating point bit level hacking i = 0x5f3759df - ( i >> 1 ); // what the fuck? y = *(float *) &i; y = y * (threehalfs - (x2 * y * y)); // 1st iteration // y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration
- return y;
- }
I created a simple parser, that runs for every ID, which is time consuming, but there's no rush.
Square root
One common method for approximating square roots with good performance is the Newton-Raphson method. Here's a simplified example:
- function sqrt(num) { guess = num / 2.0; // Initial guess // Iterate 5 times to refine the approximation for (i = 0; i < 5; i++) guess = 0.5 * (guess + num / guess)
- return guess;
- }
I recreated this function in Excel (=0,5*(B2+$B$1/B2)) to see how many passes start to produce the same output. Number up to 20 are usually fine with 3, but higher the number is, more iterations it requires to get to it. Input around 100k need 9 passes, around 1M 13 passes.
Event listeners
asdf
- elm.addEventListener("event", handler);
- elm.removeEventListener("event", handler);
what does the true/false as 3rd argument
anonymous functions:
The main advantage I find is that because it's declared inline, the anonymous function has access to all the current local variables within scope which can vastly simplify your code in some circumstances. A classic example is with setTimeout() where you want it to operate using variables defined in the scope above.
Of course, an anonymous function also doesn't interfere with whatever namespace you're in (global, local within the function, etc...) since it doesn't need a name.
A disadvantage of using an anonymous function with an addEventListener(type, fn) event handler is that you can't remove just that event listener because you don't have a handle on the function.
Another disadvantage of anonymous functions is that a new function is created every time the code that uses it runs, which in some cases makes no difference at all, but in other cases may be something to consider for performance reasons (e.g., if doing things in a loop)
asdf
Removing event listeners, beware of creating function within the code, it creates a new instance of the same function, so it won't get removed.
Subjects
I thought more about tags and found out it's even more flexible, than I imagined. All in the sense of the original idea of simplification for QetriX, tags is a generic group of anything.
It works well for users. Now tag is not only a group of users, but it acts as a role as well. You can tag users as “employee”, “customer”, “vip”
Classes in C#
asd
- class MyClass
- {
- protected void MyMethod() { }
- }
new
internal
A common use of internal access is in component-based development because it enables a group of components to cooperate in a private manner without being exposed to the rest of the application code.
public
Eric Lippert on Everything public: Modifiable, extensible and customizable code is a feature which costs money. You don't get it for free by making everything public because that causes even more problems; now the library maintains none of its invariants, and violations of invariants are called "bugs".
Identity and Access Management
I was tasked to prepare a comprehensive summary about IAM, so I learned a lot about the topic in the past few days. So to use that time even more efficiently, I'd like to share the basics with you as well.
Canvas context2d
ctx.fillRect
ctx.font
ctx.textAlign
ctx.fillText
ctx.arc
WebGL 2D, very difficult to write
Coding standards
I know the industry standard is keep lines of code up to 80 characters. Also I know my FullHD computer screen has a pivot, so I can it to "portrait" mode to see much more lines.
But I don't.
PSR
tabs vs spaces
Idiomatic CSS and JS
Async JS
setTimeout
asdf
- timed actions
- more responsive GUI, but beware of unwanted artifacts
asdf
setInterval
asdf
Promises
asdf
- return new Promise((resolve, reject) => { setTimeout(() => { resolve([1, 2, 3]); }, 1000); });
asdf
async/await
asdf
- loading scripts - await, defer
- Promises
HTML5 canvas basics
context2d
context3d
sometimes svg is better for the job
beware of UI
HTML5 canvas is a powerful element that allows you to dynamically create and manipulate graphics using JavaScript. It provides a drawing surface on which you can draw shapes, lines, text, and images.
To use the canvas element, you need to first create it in your HTML document with the <canvas> tag, like so:
- <canvas id="myCanvas" width="500" height="500"></canvas>
This creates a canvas with an ID of "myCanvas" and sets its width and height to 500 pixels each.
To start drawing on the canvas, you need to get a reference to its context object, which provides methods for drawing on the canvas. You can get the context object using the getContext() method of the canvas element, like so:
- const canvas = document.getElementById("myCanvas"); const ctx = canvas.getContext("2d");
The above code gets a reference to the canvas element with an ID of "myCanvas" and gets its 2D context object. The getContext() method takes a string argument that specifies the type of context to get, in this case "2d" for a 2D context.
Now that you have the context object, you can use its methods to draw on the canvas. Here are some basic examples:
- // Draw a line from (0,0) to (100,100) ctx.beginPath(); ctx.moveTo(0, 0); ctx.lineTo(100, 100); ctx.stroke(); // Draw a red rectangle ctx.fillStyle = "red"; ctx.fillRect(50, 50, 100, 100); // Draw text ctx.fillStyle = "black"; ctx.font = "30px Arial"; ctx.fillText("Hello, world!", 50, 150); // Draw an image const img = new Image(); img.onload = function() { ctx.drawImage(img, 0, 0); }; img.src = "myImage.png";
In the first example, we draw a line by starting a new path with beginPath(), moving the pen to (0,0) with moveTo(), drawing a line to (100,100) with lineTo(), and stroking the path with stroke().
In the second example, we fill a rectangle with red using fillRect().
In the third example, we draw text with fillText(), specifying the text, font size, and position.
In the fourth example, we draw an image by creating a new Image object, setting its onload handler to wait for the image to load, and then drawing it on the canvas with drawImage().
Psychology
Vacuum cleaners are louder, because noise is perceived as power, so quieter are considered less powerful. Also they amplify the noise of debris hitting the tube for better feeling from vacuuming.
Colors mean various stuff:
- *Black*: Strength, Elegance, High Quality, High Tech.
- *Blue*: Integrity, Trust, Security, Wisdom, Reliability, Sadness.
- *Red*: Love, Power, Heat, Speed, Urgency, Fear, Danger.
- *Green*: Envy, Wealth, Luck, Success.
- *Orange*: Happiness, Fun, Optimism, Cheapness, Caution.
- *Pink*: Romance, Youthfulness.
- *Purple*: Royalty, Magic, Courage, Creativity.
- *White*: Purity, Lightness.
- *Yellow*: Joy, Positivity, Jealousy.
https://www.empower-yourself-with-color-psychology.com/website-colors.html
Traveling Salesman
Given a list of points and the distances between each pair of points, what is the shortest possible route that visits each point exactly once and returns to the origin point?
List of coordinates, output as SVG
JSON
…I consider it a great data type
object's keys are unordered, usually ordered by name or by how properties were added.
array always preserves order of elements
Not for humans, so for better human writing emerged more forgiving formats, like JSON5 (ES5), HJSON and more. I wrote .NET implementation
There's a nice summary of all competing formats.
Relations
ER diagram editor, multipurpose
Canvas or SVG
Arrow heads
MySQL Backup in PHP
found my old solution everything by hand not working (missing keys)
SHOW CREATE TABLE
SELECT for data
Geographic coordinates
Even I like working with geographic data, to this day I'm not able to remember, what is longitude and what is latitude.
Qedy
Golfers have caddie, businesses have Qedy. Both do basically the same job – supports the star in every way possible. And there are really many ways for Qedy!
Qedy is a commercial extension of the Framework, which means most of the shared functionalities won't be open source. Qedy is purposed for rapid development of intranet and extranet information systems.
With Qedy, instead of coding, you simply create your apps in Builder, where you can see a mockup of GUI, define a data model, create label translations and more.
Qedy Logo: “ED” from rotated Q, styled as Möbius strip.
But Qedy isn't just for web apps, you can create websites with it as well! Using simple block approach you add content for the page quickly and easily. In fact, exhibit A is this blog, whose content editor uses exactly that.
With Qedy you can define component conditions, visualize them and test using defined values.
UPSERT
This strange word is a composition of UPDATE and INSERT. It's a technique, when INSERT is not possible, mostly due to key conflicts, so UPDATE is performed instead.
ON DUPLICATE KEY UPDATE
The most common UPSERT is
- INSERT INTO table (column_names) VALUES (data) ON DUPLICATE KEY UPDATE column1 = expression, column2 = expression...;
asdf
INSERT IGNORE
asdf
- INSERT IGNORE INTO table_name (column_names) VALUES ( value_list), ( value_list) .....;
asdf
REPLACE
asdf
- REPLACE [INTO] table_name(column_list) VALUES(value_list);
asdf
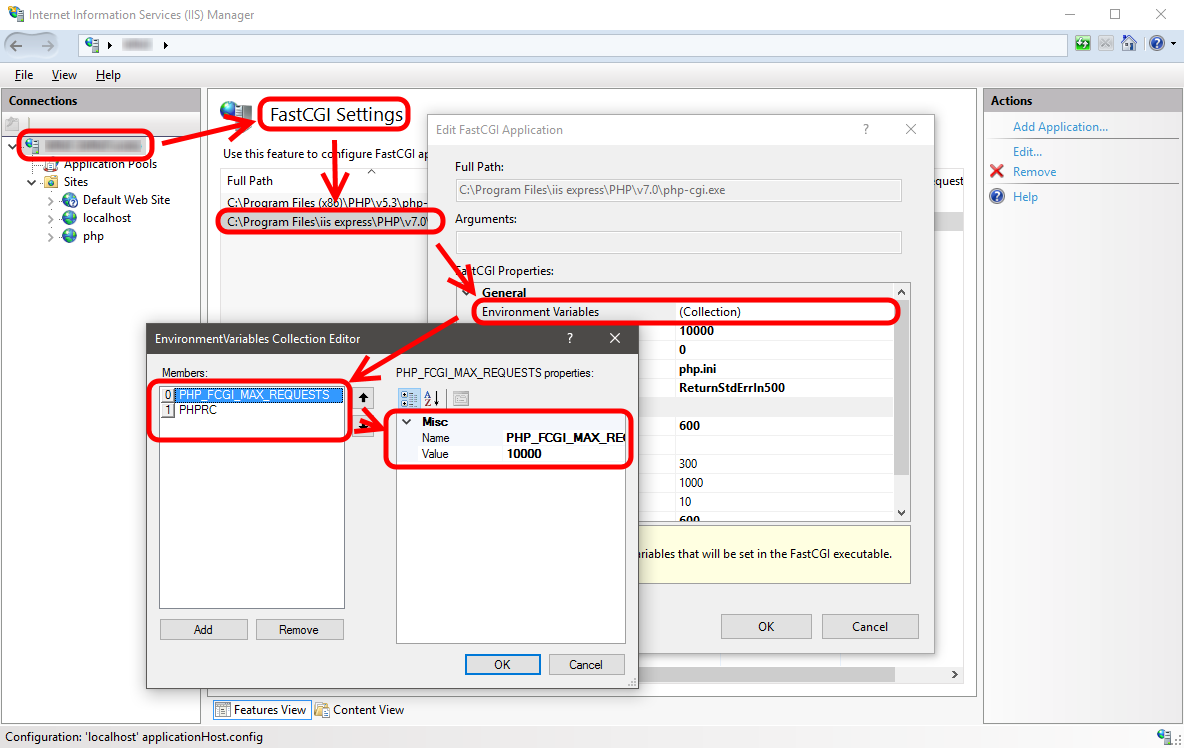
PHP on IIS
…
Slow SELECT in MySQL
DESC query
- Missing index
- Unusable index: collation mismatch
- Unusable index: %s% (only s% works)
SELECT statements in MySQL can sometimes be slow due to various reasons. Optimizing these queries is essential to ensure efficient database performance. Here are some common reasons for slow SELECT queries in MySQL and how to address them:
Lack of Indexes:
Without proper indexing, MySQL has to scan the entire table to find the required data, leading to slow SELECT queries. Ensure that you have appropriate indexes on the columns frequently used in WHERE clauses and JOIN conditions. For example:
CREATE INDEX idx_username ON users(username);
Inefficient Queries:
Complex or poorly written queries can result in slower execution. Use efficient SQL queries by avoiding unnecessary subqueries and selecting only the columns you need. Additionally, use LIMIT to restrict the number of rows returned if possible.
Large Data Sets:
SELECT queries on large tables can be slow. Consider pagination and LIMIT to fetch data in smaller chunks. This prevents the database from loading excessive data into memory.
Table Locking:
InnoDB, the default storage engine in MySQL, uses row-level locking to minimize contention. However, if your queries are not optimized or there's heavy write activity, it can lead to table locking and slower SELECT queries. Check your queries and transaction isolation levels.
Outdated MySQL Version:
Ensure that you are using an up-to-date version of MySQL. Newer versions often come with performance improvements and bug fixes.
Hardware and Server Resources:
Slow SELECT queries can also be a result of insufficient hardware resources. Make sure your server has enough CPU, memory, and I/O resources to handle the database workload efficiently.
Suboptimal Configuration:
MySQL's configuration parameters can greatly impact query performance. Tweaking settings like innodb_buffer_pool_size, innodb_log_file_size, and query_cache_size based on your system's requirements can lead to significant improvements.
Unoptimized Joins:
Complex JOIN operations can slow down SELECT queries. Ensure that you are using the appropriate types of JOINs (e.g., INNER JOIN, LEFT JOIN) and that the JOIN conditions are optimized.
Denormalized Tables:
While normalization is a good practice for database design, overly normalized tables can sometimes result in complex JOINs. Consider denormalizing certain parts of your schema if it improves query performance.
Missing Query Cache:
MySQL's query cache can help in speeding up SELECT queries, but it needs to be used judiciously. If you have frequently changing data, the query cache might not be as effective.
In conclusion, slow SELECT queries in MySQL can be attributed to a variety of factors. Proper indexing, efficient query writing, and careful consideration of the database schema can significantly improve performance. Regular monitoring and optimization are key to maintaining a high-performing MySQL database.
Unusable indexes can significantly impact the performance of your SELECT queries in MySQL. Here are some common issues related to unusable indexes and how to address them:
Using Wildcard '%' at the Beginning of a LIKE Pattern:
When you use a wildcard at the beginning of a LIKE pattern (e.g., LIKE '%str%'), MySQL can't use an index efficiently. Indexes are most effective when searching for patterns that start with a known value. To address this, you can use full-text indexing or change your query pattern to avoid the leading wildcard if possible.
Mismatched Data Types or Collations:
If the data types or collations of columns in your query don't match the indexed columns, MySQL won't use the indexes. Ensure that the data types and collations are consistent. If necessary, adjust your query or table schema to match.
Case Sensitivity Issues:
MySQL's default behavior is to be case-insensitive for indexes and comparisons. If you have a case-sensitive collation for a column but want a case-insensitive search, you can either change the column's collation or use the LOWER function to make the search case-insensitive. However, note that using LOWER may still limit index usage.
Here's an example of how to address these issues:
ALTER TABLE your_table MODIFY your_column VARCHAR(255) COLLATE utf8_general_ci;
SELECT * FROM your_table WHERE LOWER(your_column) LIKE '%str%';
Using Functions or Expressions in WHERE Clauses:
Using functions or expressions in your WHERE clauses can prevent index usage. Try to rewrite your query to use the column directly in the WHERE clause without any transformations.
Not Using Proper Index Hints:
In some cases, you may need to use index hints to instruct MySQL on which index to use. While this is not recommended for routine queries, it can be a last resort for specific scenarios. For example:
SELECT * FROM your_table USE INDEX (your_index) WHERE your_column LIKE 'str%';
Full-Text Search:
For more complex text searches, consider using MySQL's full-text search capabilities. Full-text indexes are designed to efficiently search for text within large amounts of data.
Optimizing unusable indexes in MySQL requires a combination of query design, schema design, and, in some cases, using specialized indexing techniques. Always monitor query performance and use MySQL's built-in tools like the EXPLAIN statement to understand how your queries are being executed and which indexes, if any, are used. This will help you fine-tune your database for better performance.
Order by rating
If you want to sort anything, like products or movies, by user rating, the simple method may jump into mind:
- SELECT * FROM products ORDER BY rating DESC;
Yes, it will work, but tell me, which product you perceive as better: the one with a single 5 star rating, or the other with thousands of 5 star ratings and just a few 1 stars? Because the example above will favor the first one.
The easiest remedy is to exclude those with less than a certain number of ratings, but what if you don't want to? Then you may user Bernoulli parameter, optionally with a Wilson score confidence interval.
Incorrect:
SELECT name, positive, negative, positive/total x FROM productz ORDER BY x DESC;
By the way, I'm not sure that the Wilson correction gives any better results than a one standard deviation lower bound for the positive score:
SELECT name, positive, negative, positive/total - sqrt(positive*negative/total)/total x FROM productz ORDER BY x DESC;
Score = Lower bound of Wilson score confidence interval for a Bernoulli parameter:
SELECT name, positive, negative, ((positive + 1.9208) / (positive + negative) -
1.96 SQRT((positive negative) / (positive + negative) + 0.9604) /
(positive + negative)) / (1 + 3.8416 / (positive + negative))
AS ci_lower_bound
FROM productz
WHERE positive + negative > 0
ORDER BY ci_lower_bound DESC;
Single 1 0 1
Good new 5 0 1
Excellent 23400 23 0.9988134107340426
Quite good 520 200 0.7055298549839887
Exc-ish 5 1 0.6811881781678829
Some shitty 1000 2000 0.3247267033417656
Quite bad 28 82 0.21301210856756564
Bad-ish 1 2 0.06116780616017409
Single bad 0 1 0
Single 1 0 1.0000
Good new 5 0 1.0000
Excellent 23400 23 0.9990
Exc-ish 5 1 0.8333
Quite good 520 200 0.7222
Some shitty 1000 2000 0.3333
Bad-ish 1 2 0.3333
Quite bad 28 82 0.2545
Single bad 0 1 0.0000
Excellent 23400 23 0.998
Quite good 520 200 0.688
Good new 5 0 0.565
Exc-ish 5 1 0.436
Some shitty 1000 2000 0.316
Single 1 0 0.206
Quite bad 28 82 0.182
Bad-ish 1 2 0.061
Single bad 0 1 4.586
rating = (((positive + 1.9208) / (positive + negative) - 1.96 Math.Sqrt(((positive negative) / (positive + negative)) + 0.9604) / (positive + negative)) / (1 + 3.8416 / (positive + negative)));
Naming in code
Code should be able to tell you: what, how and why.
What is method name.
How is the code itself.
Why is in the comments.
I also add vague "when", in cases I don't use CVS and file date isn't always accurate, because the last change could be just beautification or comment.
My dev beginnings
We got our first family computer on Christmas 1994. It was 486DX2 50 MHz with 4 MB RAM and 260 MB HDD, running DOS 6.22. In 1996 my older brother showed me QBASIC and I started to learn how to create a simple text game.
Later I upgraded to QuickBasic, which was able to compile to EXE.
Pascal, TurboVision
Video Memory - read box under sprite, draw sprite, put box, draw sprite on a new location. Double buffering
Created my font with added diacritics, text game with speech synthesis
Mouse, PCX, SVGA, DOS4GW
C++
PHP
C++Builder
Vypínač, Teploměr, Diskmag, Servant
Train Station announcement, Speech (slabiky)
Delphi at high school just for fun
C# in SharpDevelop